Gemini CLIの反省文
はじめに
musicRelsGraph*1は、Gemini CLIの手を借りて作りました。
AI Agentに「作ってもらう」というより、いっしょに作った感覚です。
今回は実装中の失敗・行動の傾向を、自身で記録・分析してもらい「教訓」を書いてもらいました。時に「反省文」のようになってしまいましたが、技術的な振り返り文書として整えたので内容を紹介します。
開発の中盤以降は、このドキュメントをGemini.mdに加えて読ませて作業をしました。参考になれば嬉しいです。
前提
環境と構成
- Dev Container環境 (JavaScript + node) にインストール
- Gemini CLIはGEMINI_API_KEYを使ってGemini 2.5 Proを使用
- デプロイ先はCloudflare Workersで、R2を使用
- Viteのみ、フレームワーク無し
Gemini.md
しばしば忘れ去られる、そもそも開始時に読み忘れられる。「Gemini.mdを読んで理解してください」と指示すれば一応従ってくれる。
内容はだいたい次の通りです。
- TDD
- 小さくコミット
- テスト省略条件(テスト作成で割とドツボにハマるので)
- テストガイド (AAA pattern, Mock pettern)
ドキュメント(反省文)の制作方法
作業中に解決に時間がかかった問題があったら、「この問題について、概要と困難だった点・解決に時間のかかった原因を記録し、分析して教訓を考察してください」のような指示を与えました。
いくつか問題を記録した後、問題の原因と将来同様の問題を効率的に解決するための考察をしてもらい、ベストプラクティスと規約をまとめてもらいました。
ドキュメントの概要
この記事では、個別の問題は補足事項にとどめて、開発プロセスの考察と改善策を紹介します。
ドキュメントに対して、筆者注と前提の補足をしていきます。
「問題発生の根本原因に関する考察」について
多くの問題は、単一の技術的エラーではなく、以下の複合的な要因から発生していた。
ライブラリ・APIの挙動に関する前提:
- 事象: 「ライブラリはこう動くだろう」「ブラウザはこう描画するだろう」という暗黙の前提に基づいて実装を進めてしまった。
- 分析: 外部APIの挙動は、ドキュメントで確認するか、最小限のコードで挙動を検証(プロトタイピング)する必要がある。
- 筆者注: Geminiは現状やドキュメントを確認せずに一般論による実装を行いがちでした。目の前しか見ていない……。
問題のスコープの誤認:
開発環境の特性と自己の認識:
- 前提の補足: これはCloudflareの開発ツールとViteを連携するプラグインの不具合が原因で起きた問題でした。設定を変更しても反映されない現象に対して解決まで時間がかかりました。
- 事象: ファイルを修正したにも関わらず、ブラウザ上の挙動が変わらないように見える、不可解な状況が何度か発生した。
- 分析: この原因を安易にViteのHMR(ホットモジュールリプレースメント)のキャッシュの問題であると結論付け、環境のクリーンな再起動を試みるという対応は、根本的な解決には至らなかった。真の原因は、自身のコード修正ミスや、ツールの出力内容の確認不足といった、より基本的な部分にあった。
- 教訓: 説明のつかない挙動に直面した場合、まず第一に自身の直前の変更内容を疑うべきである。ツールの問題を疑うのは、自身のコードや操作に間違いがないことを完全に確認した後に行うべき最終手段である。
- 筆者注: ここは変に「反省文」を書いてきたところです。
ツールの「魔法」への過信と、事実確認の不足:
- 前提の補足: 前項と同じプラグインの問題により発生した問題です。
- 事象: プラグインが、ドキュメント通りに動作してくれるだろう、という期待に固執しすぎた。エラーメッセージが明確に矛盾する指示しているにもかかわらず、プラグインの挙動を疑うまでに多くの時間を費やした。
- 分析: 便利なツールやプラグインは、内部で多くの処理を抽象化(=魔法のように見せる)している。しかし、その抽象化がうまく機能しない場合、憶測でデバッグを続けるのではなく、ツールの生成物を直接確認するという、基本的な事実確認のステップを早期に行うべきだった。事実を確認すれば、プラグインが設定を継承していないことはすぐに判明したはずである。
- 教訓: ツールの挙動が怪しいと感じたら、「このツールは何を生成しているのか?」というアウトプット(事実)をまず確認する。ブラックボックスのまま推測で戦わない。
- 筆者注: 「魔法」で「戦い」をしていたような言い回し……。
「推奨される開発プラクティス」について
Geminiが問題の分析に基づいてまとめた、「今後の開発で推奨されるプラクティス」は以下の通りです。
変更の確実な検証:
単純な仮説から検証:
- 問題発生時は、まず「タイポ」「セレクタの間違い」「HTML構造」など、検証が容易な単純な原因から調査する。
最小限の再現環境での切り分け:
- UIの表示など、複数の要因が絡む問題は、該当箇所だけを抜き出した最小限のHTML/JSファイルで挙動を再現させる。これにより、問題がコンポーネント単体のものか、他の要素との相互作用によるものかを迅速に切り分ける。
ビルド成果物の検証:
- ビルドやデプロイに関する問題が発生した場合、ソースコードだけでなく、ビルドプロセスによって生成された中間ファイルを直接調査する。これにより、ツールが意図通りに動作しているかを推測ではなく事実で確認できる。
エラーメッセージを第一級の情報源として扱う:
- エラーメッセージは、問題解決のための最も直接的で信頼性の高い情報源である。自身の仮説や期待よりも、エラーメッセージが示す内容を優先してデバッグの方針を立てる。
「問題解決と思考プロセスに関する規約」について
Geminiがまとめた、「開発、特にAIアシスタントと協業する際に見られた特定の思考パターンによる手戻りを防ぐための規約」です。
「理論上の最適解」より「実証された解決策」を優先する
ライブラリ固有の挙動を調査し、一般論で代替しない
- 背景: グラフ配置の処理が重いという問題に対し、ライブラリのドキュメントや特性を調査する前に、一般的な非同期化の手法を適用しようとした。
- 規約: 問題の原因が特定のライブラリやフレームワークにある場合、まず公式ドキュメント、GitHubのIssue、関連コミュニティを調査し、そのライブラリ特有のAPI(例: 非同期版メソッドの有無)、設定、既知のパフォーマンス問題、推奨される回避策を特定する。一般的な解決策(例:
Promiseでラップする)の適用は、ライブラリ固有の解決策が存在しないことを確認した後に行う。 - 筆者注: 明確に指示としてドキュメントやコミュニティーへの投稿を確認してもらうと割とましでした。
根本原因の仮説を立ててから、解決策を提案する
「魔法」を信じず、事実を観察する:
おわりに
ドキュメントと実装時の挙動から、Geminiの傾向やクセは次のようなところがありました。
- 一般論・理想論を実装しようとし、現状や固有のドキュメントのことが抜ける
- 「同じような問題」に気がつかないで、前回の初期案に近い方法を持ってくる
- 最初に検討した問題解決方法を、明らかに否定される結果が出るまで実装しようとする
- 動作確認や検証を飛ばして実装したりコミットしようとする
それから、変に指示を忖度して「反省文」を書いてくる、「魔法」とか気の利いているようで利いていない言い回しをするとか……。
なお、何をするにも「計画を立ててください」「検討してください」と、いきなり実装に進まない指示をすると実装の手戻りなく作業できて良かったです。
ちなみにテストに関しては、自分のテストへの理解度が高くないためか、Geminiもうまくできていない印象でした。対象への理解度がAIへの指示精度にも連動して影響するのでしょう。
Geminiがやらかしがちなことへの対策として、「推奨される開発プラクティス」「問題解決と思考プロセスに関する規約」が参考になれば幸いです。
アーティスト・楽曲・制作者のつながりを可視化するウェブアプリmusicRelsGraphを作った
はじめに
musicRelsGraphは、楽曲とアーティスト・制作者をつないで可視化するウェブアプリです。
いまのところは「ホロライブ」「にじさんじ」「アイドルマスター」の楽曲データ*1を表示できます。
- 「このアーティストがよく関わっている作詞家・作曲家は誰だろう?」
- 「制作者から楽曲やアーティストを掘っていきたい。」
- 「つながりを見ると、この人とあの人の楽曲は近いグループだ。」
- 「えっ、この曲もあの曲も、同じ人が作ってたの?」
- 「推しのアーティストとあの人がコラボしてた!」
眺めているだけで、こんな新しい発見ができます。
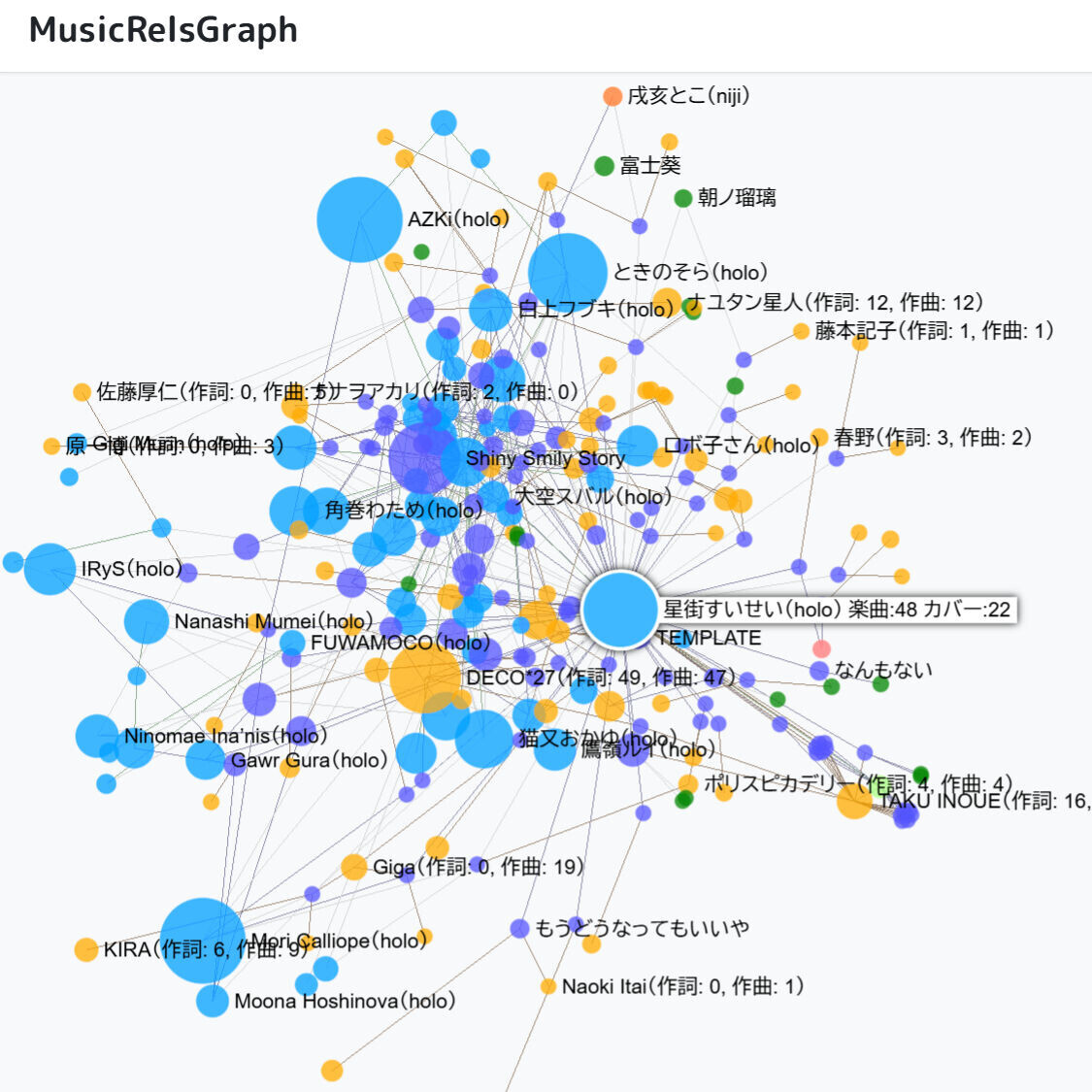
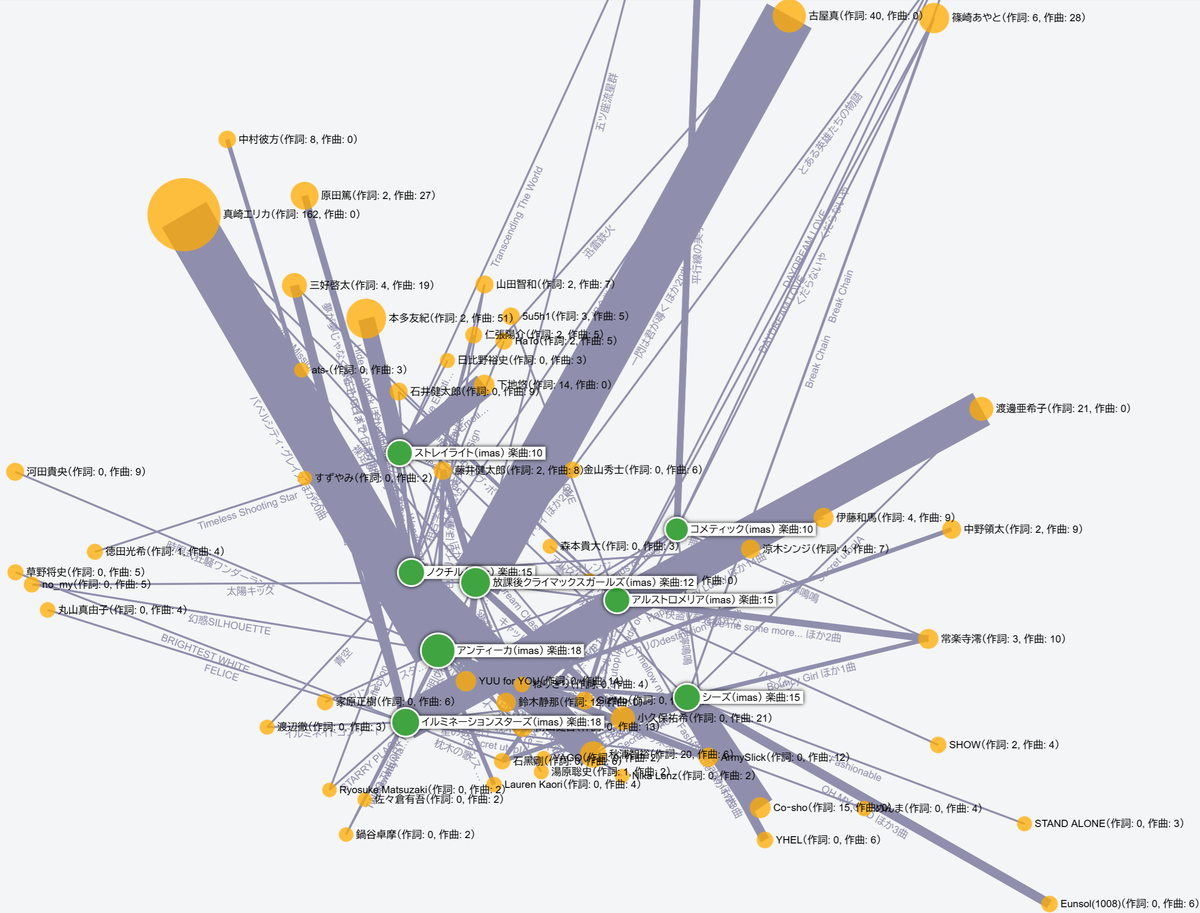
使いかた
- 🔍 さがす:拡大や強調表示、検索・表示調整で、知りたい楽曲やアーティストを探す
- 👆 選ぶ:気になるところをタップ・クリック
- ✨ 発見:関連する楽曲・人物が強調表示
基本はこれだけです。楽しんでくださると嬉しいです。
続いて、何ができるか一通り説明します。
データセットを選ぶ
画面上にあるデータセットメニューから、データを選んで切り替えできます。

アイドルマスターが含まれているデータセットは、サイズが大きいので表示に時間がかかります。
🔍 拡大縮小
二本指で広げたり、マウスホイールで拡大・縮小できます。
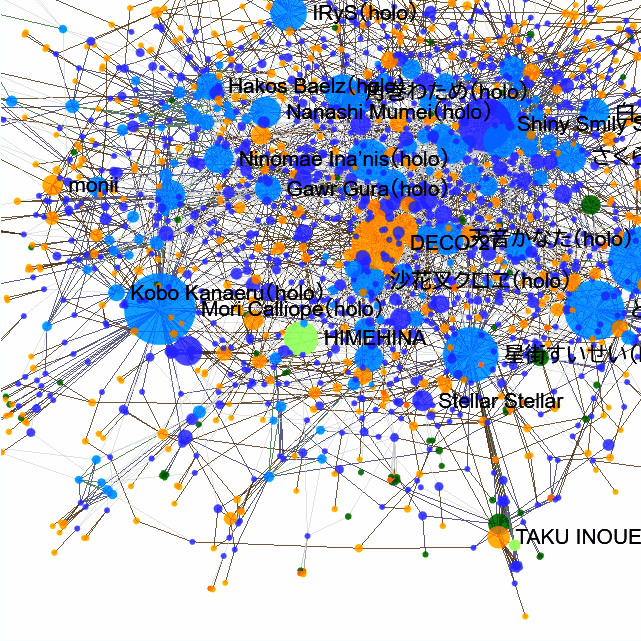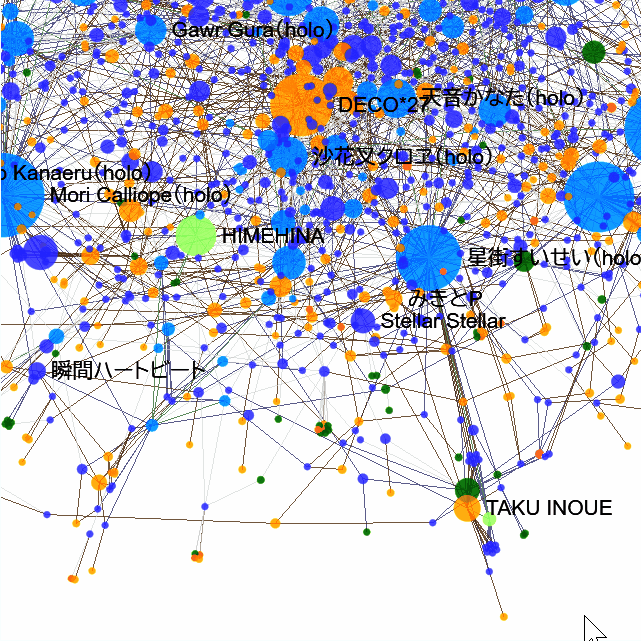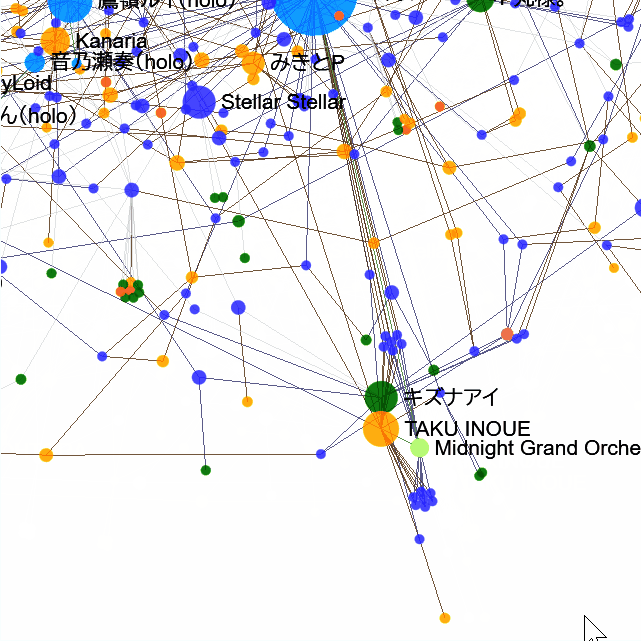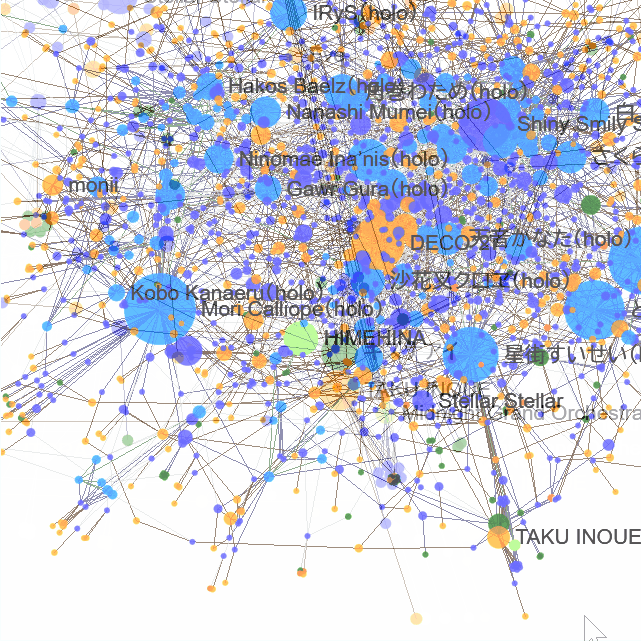
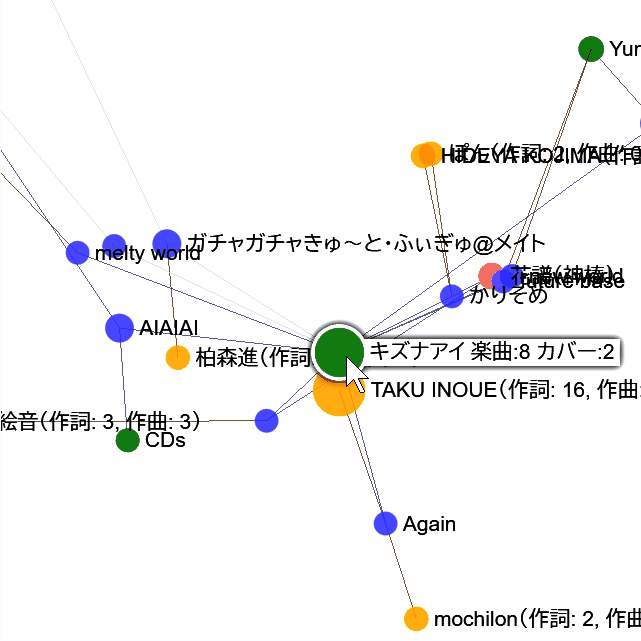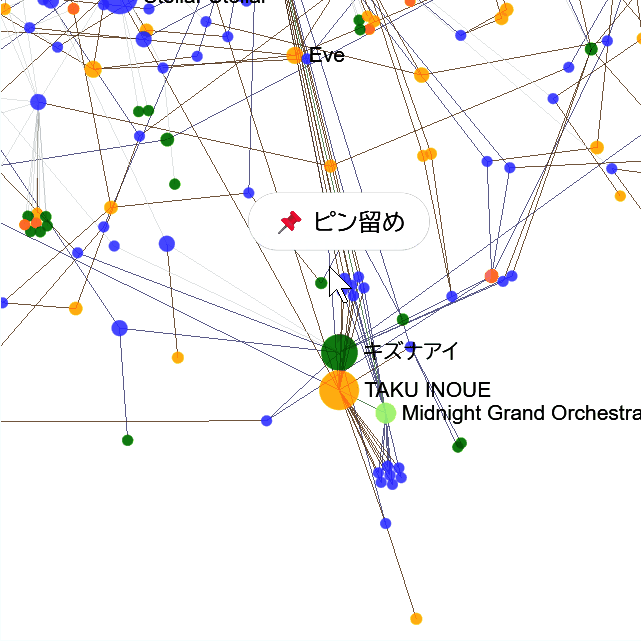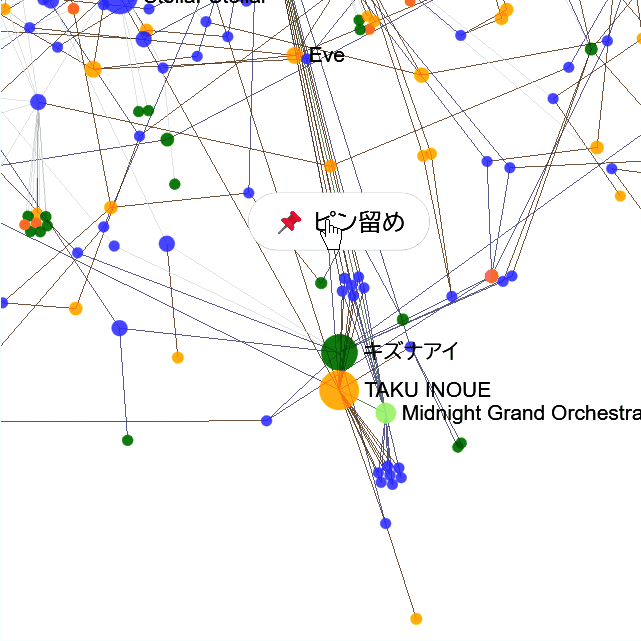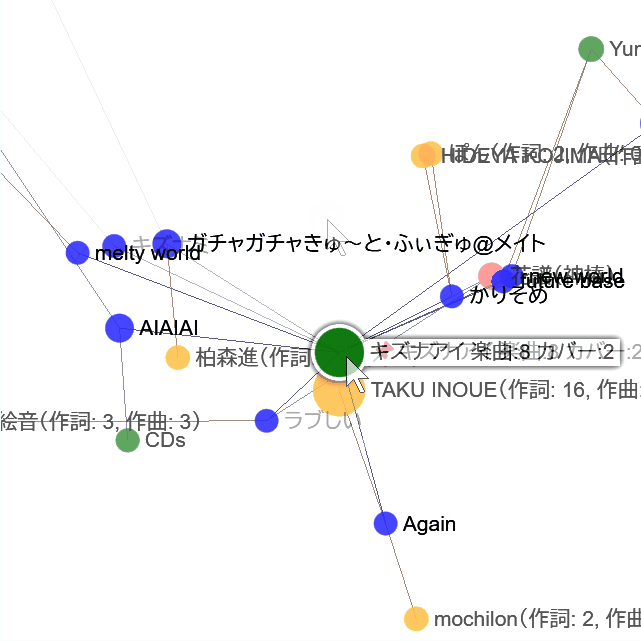
📌ピン留め
タップまたはクリックで、曲やアーティストなどをピン留めすると、周りのつながりだけ見られます。解除も、ピン留めされた要素をタップまたはクリックするとできます。
- 「アーティスト」をピン留め: そのアーティストが歌った楽曲、所属グループのみ表示
- 「楽曲」をピン留め: その楽曲を歌った人、制作者のみ表示
- 「制作者」をピン留め: 制作した楽曲のみ表示
🔗リンク表示
楽曲アイテムに関連リンクがある場合は、タップまたはクリックでリンク一覧も表示されます。
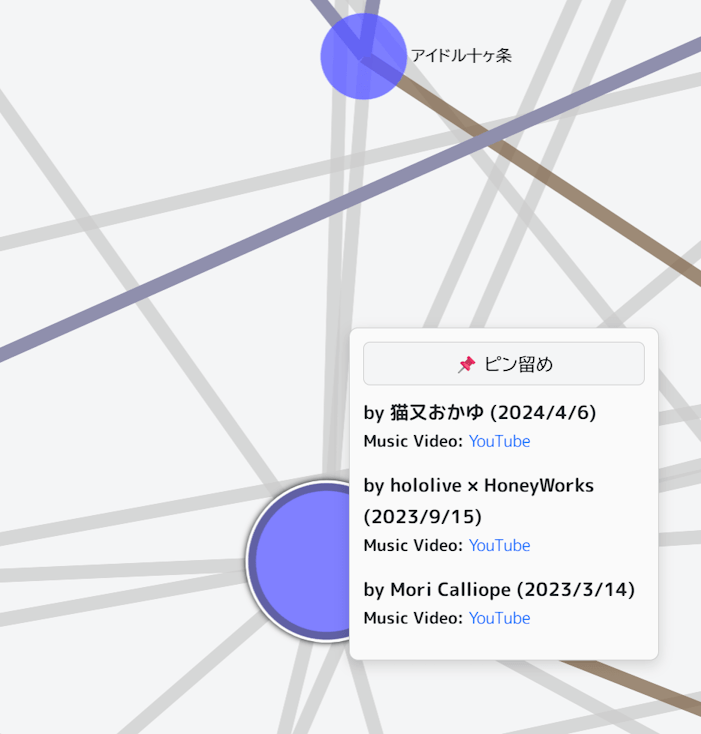
リンクのある楽曲アイテムは、枠線があります。
✨強調表示
※サイドバーの「曲やアーティストにふれたときに関連を強調表示する」にチェックが入っている必要があります。
曲やアーティスト・制作者をタッチまたはホバーすると、要素の隣の隣までを強調表示します。
サイドバー
メニューボタンを押して、開け閉めできます。

選択したデータセットの説明や、検索・表示の調整設定・フィルターなどがあります。
表示調整
- 曲やアーティストにふれたときに関連を強調表示する
- タッチやホバーでの強調表示切り替え。モバイル表示では初期値はオフです。
- オリジナル曲・カバーされた曲のみ表示
- オリジナル曲もしくはカバーされた楽曲のみの表示にします。(データセット内のアーティストによってカバーされたかどうか)
検索
文字をボックスに入力すると、一致した要素と、その隣だけが表示されます。半角スペース区切りでOR検索します。
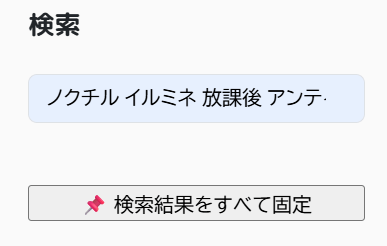
検索でマッチした項目を、全てピン留めすることもできます。
つながりの多さ
それぞれの要素から出ている線を「つながり」として数えています。ここで設定したつながりの数より大きい要素だけ表示できます。
所属・グループ
アーティスト要素のラベルについている、カッコ書きの「holo」「niji」「imas」などが所属・グループです。チェックを外した所属・グループは表示されません。
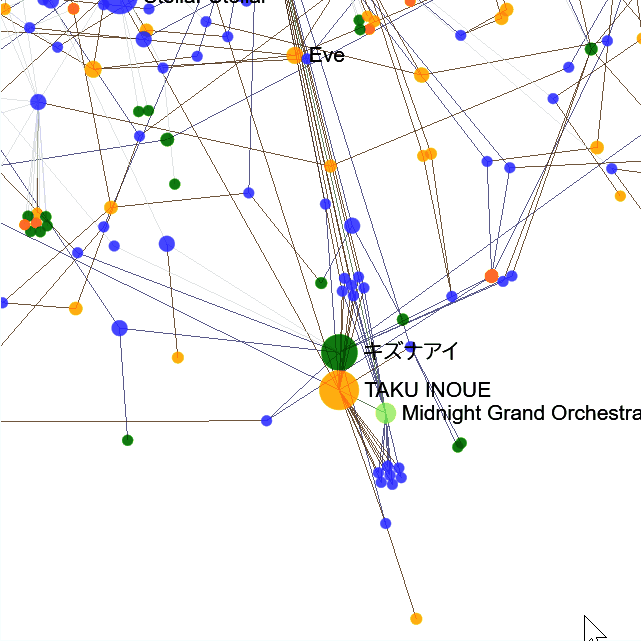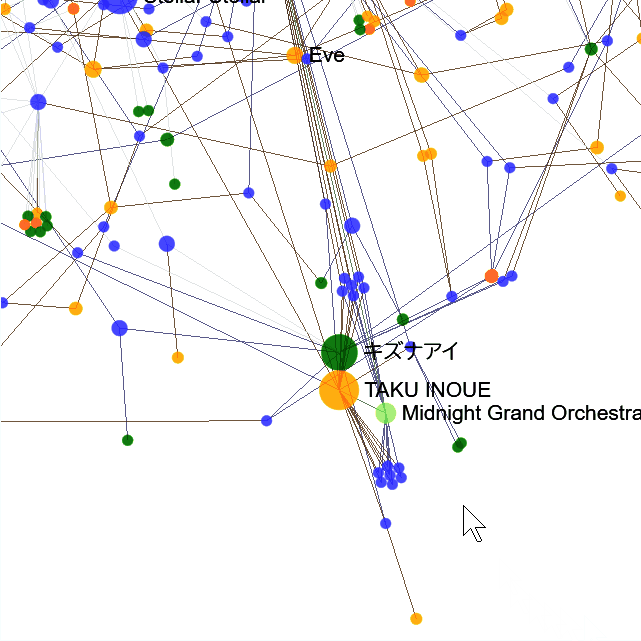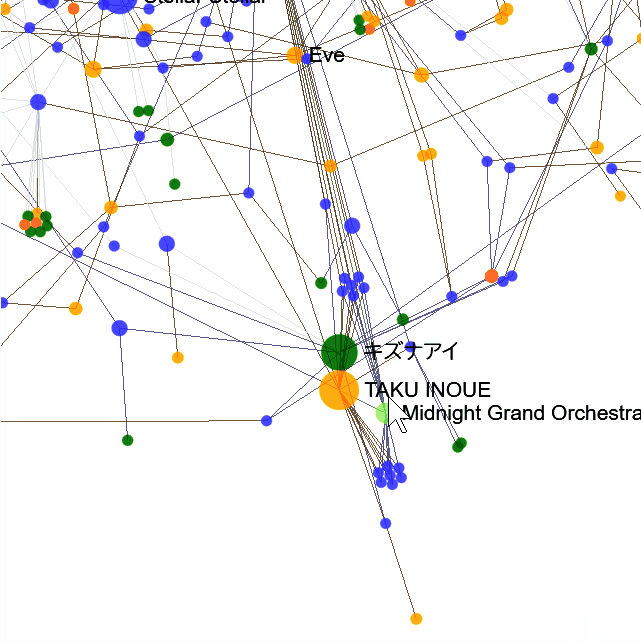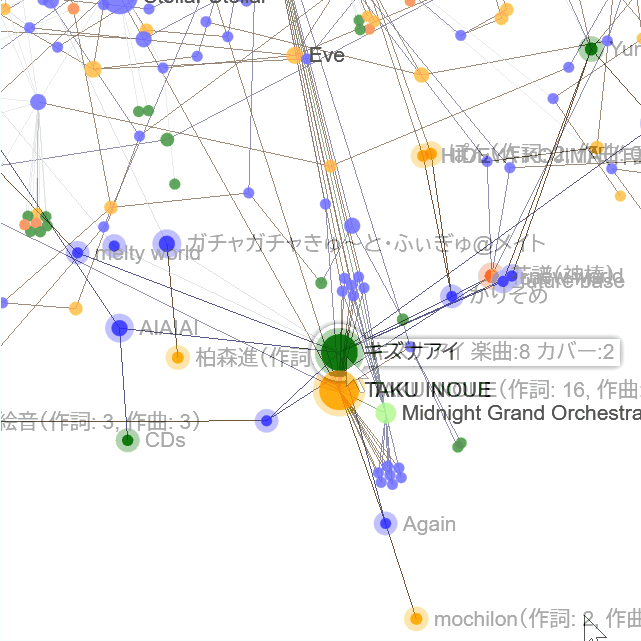
統計情報
表示中データの統計情報
フィルター適用後のノードやエッジの情報を示します。
表示される情報は以下の通りです。
- 種類ごとのノード数
- artist, credit, group それぞれのノード数
- 所属・グループごとのノード数
- holo, niji, imas それぞれのノード数
- エッジの種類ごとの数
- cover, original ごとの数
- 種類ごとの上位ノード
- artist, credit, group それぞれつながりの多いノード上位3つ
- 所属・グループごとの上位ノード
- holo, niji, imasなど、それぞれつながりの多いノード上位3つ
- その他の統計情報
- 平均次数, 最大次数, 最小次数
基本統計情報
同じようなデータですが、データセット全体のデータを示します。
補足
ページを更新したりデータセット切り替えごとに、配置は変更されます。
データソースとしたMusicBrainz Databaseには、入力されていないデータがいくつもあります。MusicBrainzは誰でも貢献可能なオープンな音楽情報ソースです。
お気づきの足りないデータはMusicBrainzに貢献*2していただけると有りがたいです。
データの更新はお約束できませんが、興味の向く限りメンテナンスするつもりです。
*1:MusicBrainz (https://musicbrainz.org/) のデータベースを利用しています
*2:今回は200曲くらい入力しました
Chromadbのテキスト埋め込み関数でGPUを使う
はじめに
Chromaのデフォルトテキスト埋め込み関数(ONNXMiniLM_L6_V2)は、GPUの使用をサポートしている。
nVidiaのGPU(cuda環境)ならonnxruntime-gpuをインストールして、関数の引数 preferred_providers にGPUをサポートするプロバイダーを設定する。
今回はAMD Radeon RX6600Mなので、onnxruntime-directmlをインストールした。
結果としてCPUより約4倍速くドキュメントを登録出来た。
なお残念ながら、Sentence Transformersモデルでの動作はサポートしていない*1とみられる。
手順と検証
# インストール pip install onnxruntime-directml
# 使用できるプロバイダを表示するスクリプト import onnxruntime print(onnxruntime.get_available_providers()) # ['DmlExecutionProvider', 'CPUExecutionProvider']
# ベンチマークスクリプト
import time
from chromadb.utils.embedding_functions import ONNXMiniLM_L6_V2
provider = 'CPUExecutionProvider'
ef = ONNXMiniLM_L6_V2(preferred_providers=[provider])
docs = []
for i in range(1000):
docs.append(f"this is a document with id {i}")
start_time = time.perf_counter()
embeddings = ef(docs)
end_time = time.perf_counter()
print(f"Elapsed time: {end_time - start_time} seconds with {provider}")
結果
| Dml | CPU | |
|---|---|---|
| 1回目 | 6.50 | 25.09 |
| 2回目 | 6.39 | 24.69 |
| 3回目 | 6.28 | 25.94 |
| 4回目 | 6.36 | 25.45 |
| 平均 | 6.38 | 25.29 |
環境は以下の通り:
参考
ONNXモデルを内蔵GPUで推論する。 onnxruntime-directmlについては、この記事で知った。
WSL2でMoore-AnimateAnyoneを試してみる DmlExecutionProviderが見つからない時があったのですが、onnxruntime-directmlだけをインストールする必要があった。 1. uninstall - onnxruntime - onnxruntime-gpu - onnxruntime-directml 2. install - onnxruntime-directml
Embedding Functions GPU Support 公式ドキュメントはonnxruntime-gpuでの例となっている。
*1:そもそもDirectMLでTextEmbeddingモデルを動作させようとするとエラーが発生する
動画をプログラムで作るRemotion
動機と結果
インフォグラフィックスを動画形式で作成したい。
今回は、Remotionで作成しました。
作成した動画はこちら。
「エビ揉め」動画ブームの動画を作った#ニコニコ動画https://t.co/6QkV9ys3uu pic.twitter.com/uHkdoJMEQN
— あふひねこ(あおいと読む) (@AOI_CAT) 2024年9月4日
背景
これまではD3.jsを使っていました。
D3.jsは、データを扱いやすく、アニメーション表示や、インタラクティブなグラフも作れます。
しかし、動画となると少し手間がかかります。
そこで適したツールがないかと探して見つけたRemotionを試しに使ってみました。
Remotion
Make videos programmatically.
Create real MP4 videos using React. Scale your video production using server-side rendering and parametrization.
- Reactベース
- 動画の各要素をコンポーネントで作成・配置
- ボタン(コマンド)一発でCompositionをMP4(h264)に描き出し
構造と理解
graph LR; Root["Root"] Composition1["Composition 1 duration frames / fps / width / height"]; Composition2["Composition 2"]; CompA["Component A"]; CompB["Component B"]; CompC["Component C"]; Root --> Composition1 -- defaultprop --> CompA -- prop --> CompB; Root --> Composition2 --> CompC;
Componentではframeやデータに応じた処理をする。
<Sequence from={duration}></Sequence>で表示開始時間を制御frame = useCurrentFrame()でframeに応じた処理- propやfetchしたデータに応じた処理
所感
前提としてReactについて不案内なため、そちらの学習や手間はかかった。
データの受け渡しの都合上、各コンポーネントが連携したものは大変そう。作った動画の場合は、総動画数の表示に苦労した。
コンポーネントの配置や調整は直感的だった。
表示時間の調整など、frame単位の処理は少し煩雑に思えた。
コンポーネントごとにまとまるので、コードの見通しが良い。ただし、1ファイル完結でサクッと作るといった目的には少し煩雑に思えた。
D3.jsの代わりになるかというと、目的が違うツールの印象。もちろん、複雑なグラフはD3.jsの方が得意。
既存のグラフではなく、データに基づいた配置などを組み立てて、時間経過を見せる動画を作る用途に向いているように思える。
日本語文のベクトル化と、ベクトルDB Chromaへの登録・検索をローカル環境で実行する
はじめに
このごろ多様なベクトルデータベースが開発されていますが、これまで扱ったことも基本的なことも知らないままでした。
そこで日本語の処理を念頭にして調査のうえ、実際に手を動かして扱いを確認しました。
この記事は、高い性能を示した日本語文埋め込みモデル(cl-nagoya/sup-simcse-ja-base)を用いて日本語文をベクトル化し、Chromaデータベースに登録して検索を行うまでの一連の作業メモです。
調査
日本語文のベクトル化について
日本語文をベクトル化することで、類似文の検索や自然言語処理タスクに利用できます。多くのモデルが利用可能ですが、本記事ではローカル環境で動作する「cl-nagoya/sup-simcse-ja-base」を選びました。これは、APIを介さずにローカルで動作するため、データプライバシーの観点からも有利です。
文章のチャンク化について
文章をベクトル化する前に、適切なチャンクに分割する必要があります。今回は適当にLLMのトークン処理設定を目安に最大384文字でチャンク化しました。
日本語文の区切りについて
今回は単純に改行区切りで処理をしました。
場合によっては、文章の区切りを自動的に判別する必要があります。GiNZAやja-sentence-segmenterを使用することで、より精度の高いチャンク化が可能でしょう。
参考: 日本語の文章をいい感じに文区切りするライブラリを作った
日本語文章の準備
今回は青空文庫のデータを使用します。以下のコードで、作家一人分のデータを取得し、前処理を行います。
前処理の具体的な手順は、参考の記事を見てください。
参考: Pythonで青空文庫データを自然言語処理向けにさくっと一括テキスト整形+前処理
なお、記事中にあるsvnを使用してのダウンロードはうまくいきませんでした。 そのため https://download-directory.github.io/ を利用しました。
Chromaへの登録
以下は、Chromaに日本語文を登録するためのコード例です。基本的な手順は公式のドキュメントの通りです。
import chromadb from chromadb.utils import embedding_functions # データを保存するためのPersistentClientを作成 chroma_client = chromadb.PersistentClient(path="./chroma") # Sentence Transformerのモデルを指定して、embedding functionを作成 sentence_transformer_ef = embedding_functions.SentenceTransformerEmbeddingFunction(model_name="cl-nagoya/sup-simcse-ja-base") collection = chroma_client.create_collection( name='my_collection', embedding_function=sentence_transformer_ef ) # 日本語文を追加 texts = ["吾輩は猫である。名前はまだ無い。", "どこで生れたかとんと見当がつかぬ。"] collection.add( documents=texts, metadatas=[{ title="吾輩は猫である", chunk="1"}, { title="吾輩は猫である", chunk="2"}], ids=["id1", "id2"] )
検索
今回は「宮沢賢治」の作品データをベクトル化しました。以下のクエリテキストに似た文章が含まれるチャンクを検索しました。
クエリ
クエリテキストは賢治が篤く信仰した法華経の一説です。
results = collection.query(
query_texts=["我れ深く汝等を敬う、敢て軽慢せず、所以は何ん、汝等皆菩薩の道を行じて、当に作仏することを得べし"],
n_results=3
)
print(results)
結果
{'ids': [['id_2782', 'id_2462', 'id_878']], 'distances': [[130.5767822265625, 138.81564331054688, 183.30587768554688]], 'metadatas': [[{'title': '不軽菩薩\n', 'verse': 1}, {'title': '疾中\n', 'verse': 13}, {'title': 'ビジテリアン大祭\n', 'verse': 46}]], 'embeddings': None, 'documents': [['あらめの衣身にまとひ\n城より城をへめぐりつ\n上慢四衆の人ごとに\n菩薩は礼をなしたまふ\n(省略)', 'われ死して真空に帰するや\nふたゝびわれと感ずるや\n(省略)', '「マットン博士の神学はクリスト教神学である。且つその摂理の解釈に於て少しく遺憾の点のあったことは全く前論士の如くである。然しながら茲に集られたビジテリアン諸氏中約一割の仏教徒のあることを私は知っている。私も又実は仏教徒である。(省略)']], 'uris': None, 'data': None}
クエリテキストに似た文章が含まれるチャンクが結果に返ってきているようです。
ベクトル化文の足し引き
word2vecで有名な「王」−「男」+「女」=「王妃」の足し引きと同じように、ベクトルを足し引きして検索できます。
from sentence_transformers import SentenceTransformer import numpy as np model = SentenceTransformer("cl-nagoya/sup-simcse-ja-base") # 足し引きする文をベクトル化 embedded = model.encode(["我れ深く汝等を敬う、敢て軽慢せず、所以は何ん、汝等皆菩薩の道を行じて、当に作仏することを得べし"]) embedded2 = model.encode(["仏教"]) # numPyで計算 embedding = np.array(embedded) - np.array(embedded2) # query_embeddingsパラメーターにセットして検索 results = collection.query(query_embeddings=embedding) print(results)
結果:
{'ids': [['id_1537', 'id_2284', 'id_1519']], 'distances': [[391.4697265625, 404.6991882324219, 413.8621520996094]], 'metadatas': [[{'title': '二十六夜\n', 'verse': 29}, {'title': '二十六夜\n', 'verse': 29}, {'title': '二十六夜\n', 'verse': 11}]], 'embeddings': None, 'documents': [['悪業を以ての故に、更に又諸の悪業を作ると、これは誠に短いながら、強いお語ぢゃ 。先刻人間に恨みを返すとの議があった節、申した如くぢゃ、一の悪業によって一の悪果を見る。(省略)']]}
コード
ローカル環境でAI翻訳 (NLLB200 Model)
はじめに
Meta AI製のモデルNLLB-200*1を使って、ローカルで翻訳をできるようにした。
Gradioを利用した簡易UIでブラウザーから翻訳できます。
性能
速度はAMD Ryzen 9 5900HX、メモリ32GBで、以下の文章の翻訳に1分くらいです。
Alice was beginning to get very tired of sitting by her sister on the bank, and of having nothing to do: once or twice she had peeped into the book her sister was reading, but it had no pictures or conversations in it, “and what is the use of a book,” thought Alice “without pictures or conversations?”
So she was considering in her own mind (as well as she could, for the hot day made her feel very sleepy and stupid), whether the pleasure of making a daisy-chain would be worth the trouble of getting up and picking the daisies, when suddenly a White Rabbit with pink eyes ran close by her.
The Project Gutenberg eBook of Alice’s Adventures in Wonderland, by Lewis Carroll
翻訳結果
アリスは,銀行で彼女の妹の隣に座って,何もしないことにとても疲れて始めていた:一度か二度彼女は彼女の妹が読んでいた本に覗いて,しかしそれは,その中に写真や会話がなかった,そして,それは何の本の使用ですか,アリスは考えました,写真や会話なしで? 彼女は,彼女の心に考えていたので, (彼女ができたように,暑い日は彼女が非常に眠くて愚かと感じた),ダージーチェーンを作る喜びが立ち上がって,ダージーを拾うのトラブルに価値があるかどうか,突然ピンクの目を持つホワイトラビットが彼女の近くで走ったとき.
まぁ、何となく意味が取れる程度ですね。
実装
使い方
install.shの手順のあとpython NLLB-200_app.pyして、起動したらブラウザーで 127.0.0.1:7860 を*2開きます。
参考
LLMをWindowsローカルマシンで実行し、AMD RX6600Mを使う。(LM Studio, KoboldCpp-rocm)
はじめに
AMD RX6600M GPUを搭載したWindowsマシンで、テキスト生成用途にLLM実行環境を試したときのメモです。
LM Studio、Ollama、KoboldCpp-rocm、AnythingLLMの各ソフトウェアの使用感、GPU動作について紹介します。
結論として、この中ではLM StudioとKoboldCpp-rocmがAMD RX6600Mを利用して動きました。
モデルについて
LM Studio、KoboldCpp-rocmについては、GGUF形式にしたモデルを読み込みます。
こちらからMeta-Llama-3-8B-Instruct-Q4_K_Mを読み込ませて使用したところ、一瞬PCが重く感じる場面もありましたが動作しました。
なお自分が触った範囲では、MetaのLlama 3が最も頭が良さそうな回答をしてくれました。(ただし通常の回答は英語)
使用感と利点・欠点
1. LM Studio
LM Studioは、モデルの検索から実行、対話までを一貫して行えるUIを持っています。サーバーとしてバックエンドで使用することも可能です。
これだけで実行に必要な全てが揃い、手間がかかりません。
AMDのBlogでも紹介されています: How to run a Large Language Model (LLM) on your AM... - AMD Community
利点
- 単体で完結する
- 一貫したUIで操作が簡単
- 細かい設定の変更も可能
欠点
2. Ollama
OllamaはCLIベースで動作するLLMローカル実行ソフトです。GUIは別途用意する必要があります。多くの実行環境に組み込まれたり、サーバーに使われているようです。
利点
- モデルのダウンロードと実行が簡単
- 使用実績が多い
欠点
なお、バージョン0.2.23で動作します。
3. KoboldCpp-rocm
KoboldCpp-rocmは、紹介する中で唯一AMD RX6600Mを使って動きました。細かい設定が可能で、また特徴的な使い方があります。
KoboldCppのROCmライブラリ対応版です。
利点
- AMD RX6600Mを利用可能
- コンテキストやシナリオなどの多様な設定が可能
欠点
- ドキュメントが少ない
- UIや用語、動作を理解する必要がある
導入と設定
起動すると設定画面が出ます。
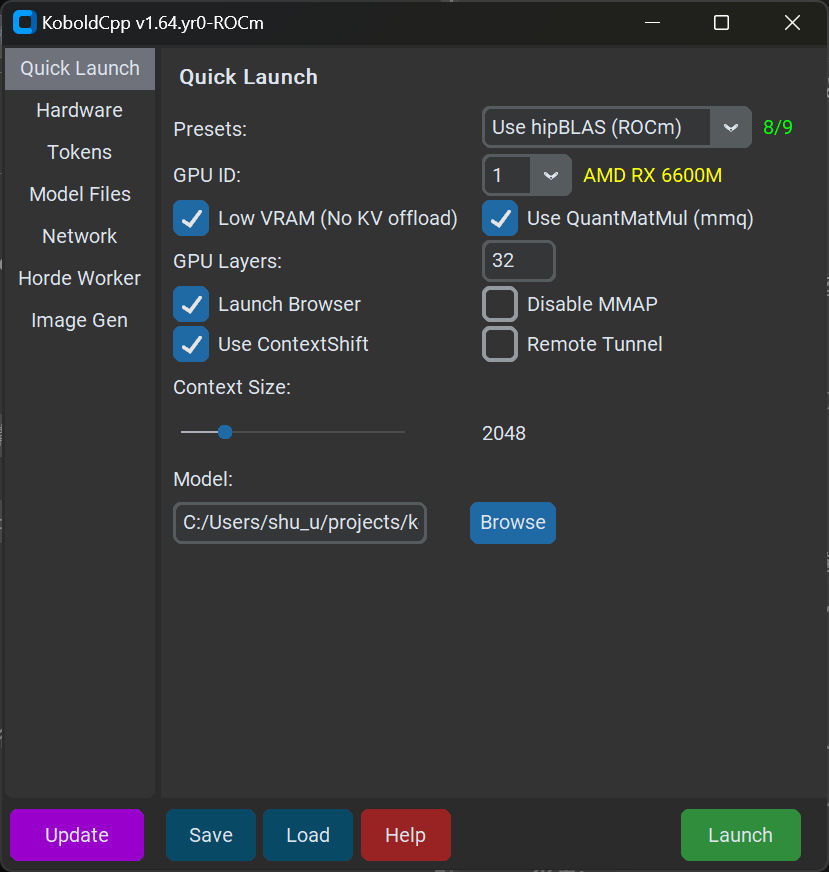
デフォルトから変更したのは以下の通りです。
- Low VRAMにチェック
- GPU Layersを32
- Modelを選択
LowVRAMのチェックを外すと、回答中にAccess Violationで落ちることあります。Context Sizeを小さくすればある程度防げますが、こちらにチェックをしたほうが安定します。
速度は遅くなるようですが、そもそも初回の回答に数十秒(ContextとプロンプトToken数による)、それ以降も10 token/sくらいなので体感としてはあまりわかりませんでした。(それでもCPU動作より速い)
Launchボタンを押すと起動してブラウザーのウィンドウが開きます。
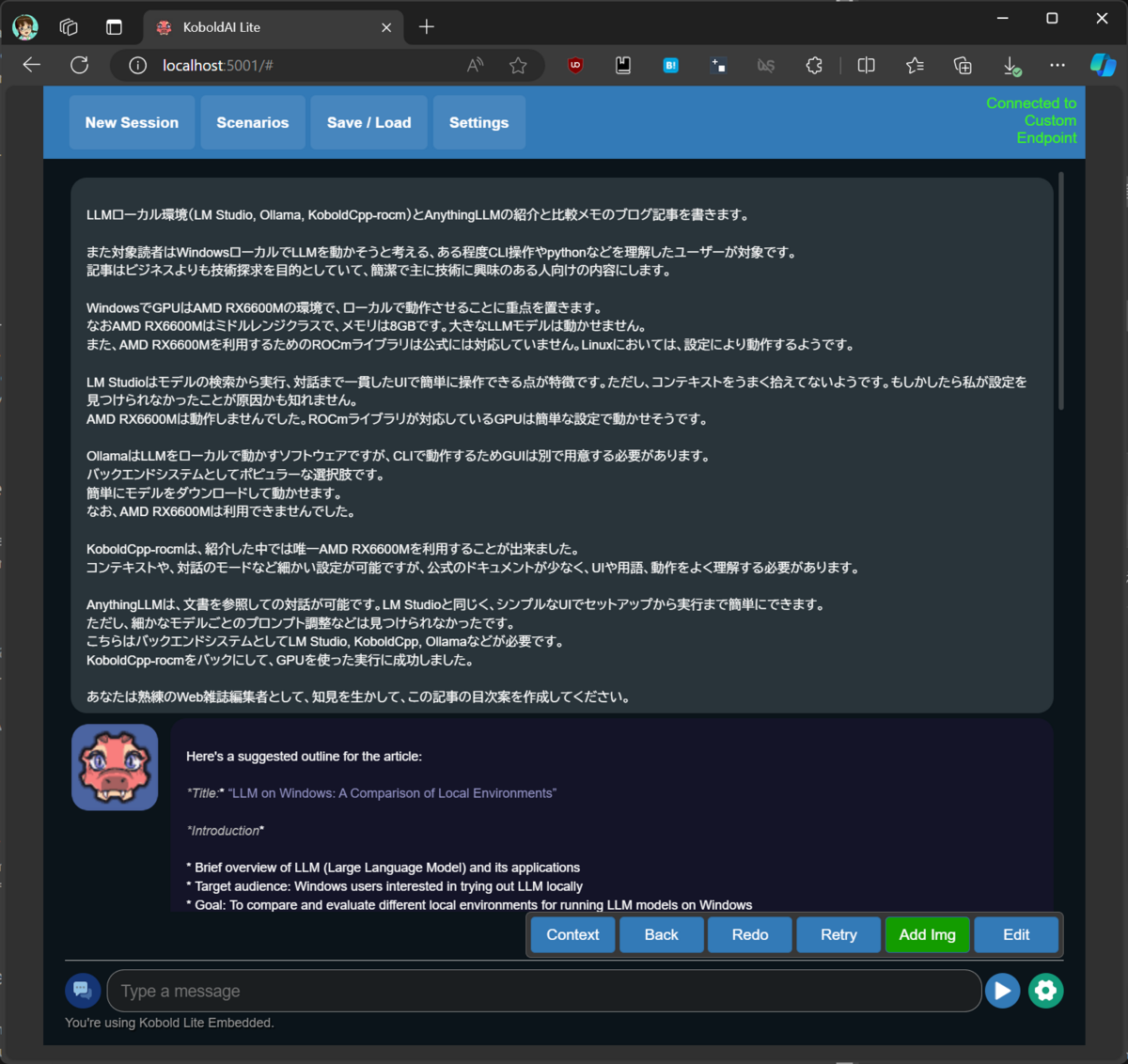
Settingsを開き、FormatをInstruct Mode、 Instruct Tag PresetをLlama3 Chatにします。
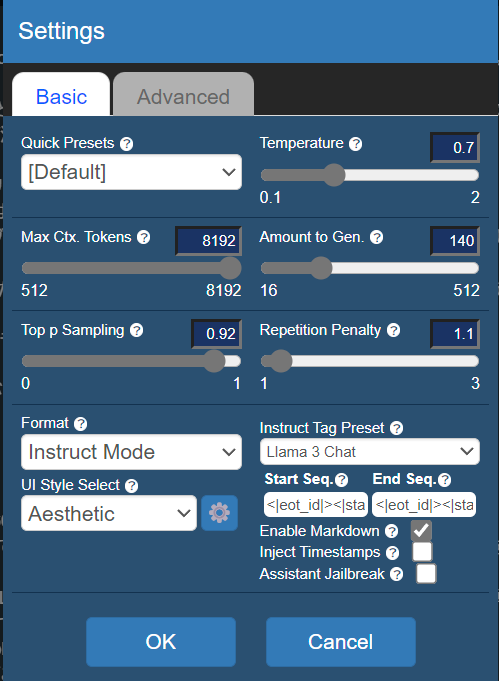
Contextから毎プロンプトごとに送るMemoryを設定できます。
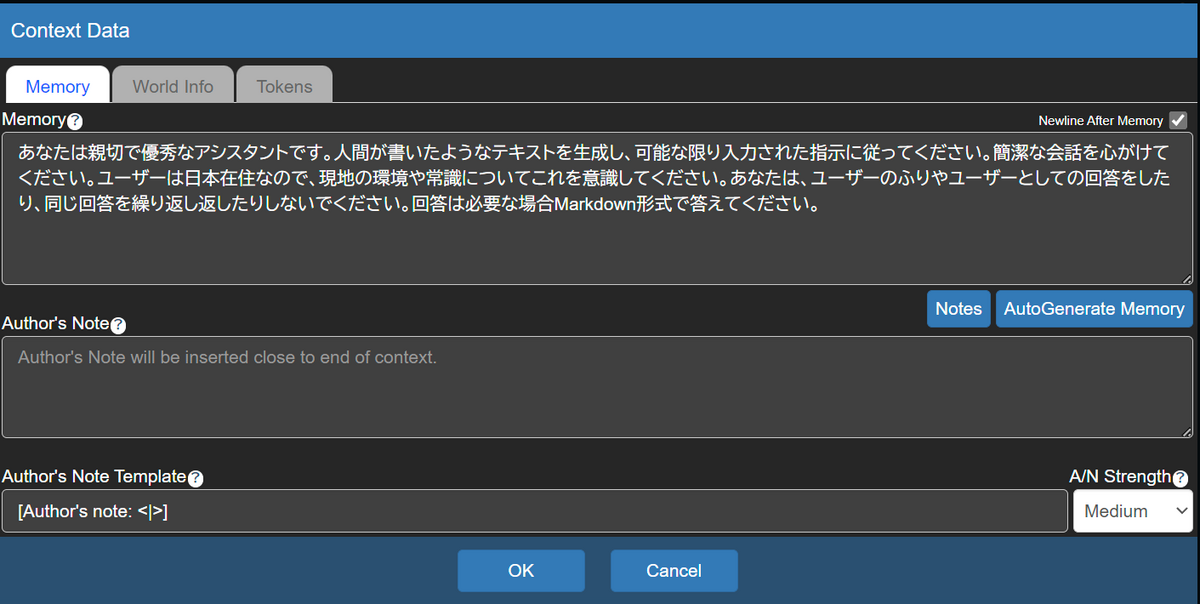
あとはメッセージを送れば対話できます。
なお、MemoryやSessionの設定・用語を見るとわかるとおり、Koboldはキャラクターや世界観を保ったままストーリー生成やRPGのセッションを行う目的が強いようです。
4. Anything LLM
Anything LLMは、アップした文書を参照させて対話することが特徴です。LM Studioと同様にシンプルなUIです。
バックエンドとしてOllama, LM Studio, KoboldCppやクラウド上のAPI接続など他のシステムが必要です。
AMDのBlogでも紹介されています: How to enable RAG (Retrieval Augmented Generation)... - AMD Community
利点
- シンプルなUIで簡単にセットアップ可能
- 文書参照機能
- LM Studio, KoboldのAPIで動作するのでRX6600Mを利用できる
欠点
- 細かなモデルごとのプロンプト調整などが難しい
- UIは一貫しているが、細かい設定はなく長い回答が分割されたりする
まとめ
Windowsローカル環境でAMD RX6600Mを利用したいならLM StudioかKoboldCpp-ROCmを使う。
文書参照をしたいならAnything LLMを使う。
なおLM Studioが一番簡単ではありますがKoboldCppは多様な機能を持っているので、小説生成・シナリオ作成などの用途ではKoboldCppが適しているのではないかと思います。